December 8, 2019
Moving large amounts of content across a diverse network environment happens to be one of my specialties that I have focused a better part of my career on over the last 12+ years. Basically it boils down to how to get the least amount of data from point A to point Z, across several networks in the most efficient manner possible, in the shortest amount of time, all without clobbering the network and systems that are touched. If you have done any kind of operating system deployment in the last decade, then you know operating systems and related content are getting larger, not smaller, and the network links are not increasing at the same pace. This is not your typical party conversation topic, so if you are bored already then feel free to head back to Twitter, Facebook or whatever you like doing. Otherwise, feel free to stick around and maybe this will give some inspiration or help you in some way with your network struggles.
I have been meaning to write about this topic for a while, since I presented on this at MMSMOA last May with my good friend Andreas Hammarskjold. However, as some of you that follow me on Twitter might know, I have taken up interest in Tesla lately and have been spending my extra time outside of work racing and tweaking my new Model 3 Performance which awesome car BTW and runs 11.5s in the quarter mile (shameless plug – referral link in my Twitter profile). Plus, my colleague Gary Blok is much younger and tends to beat me when it comes to blogging anything WaaS/IPU lately. I’ll say something like ‘man, this is awesome, we should totally blog this’, only to wake up the next morning to find out he did that night (I don’t think he sleeps).
This is going to focus on driver packages, however, it can be used for any time of content (like large software packages). At MMSMOA, I used Dell driver packages as the example, but I want to show that the same efficiencies can be gained using HP (or any vendor). I am not going to spend any time on what data deduplication is or how it works, or how to setup and use BranchCache, however these are two of the main technologies that make this all possible.
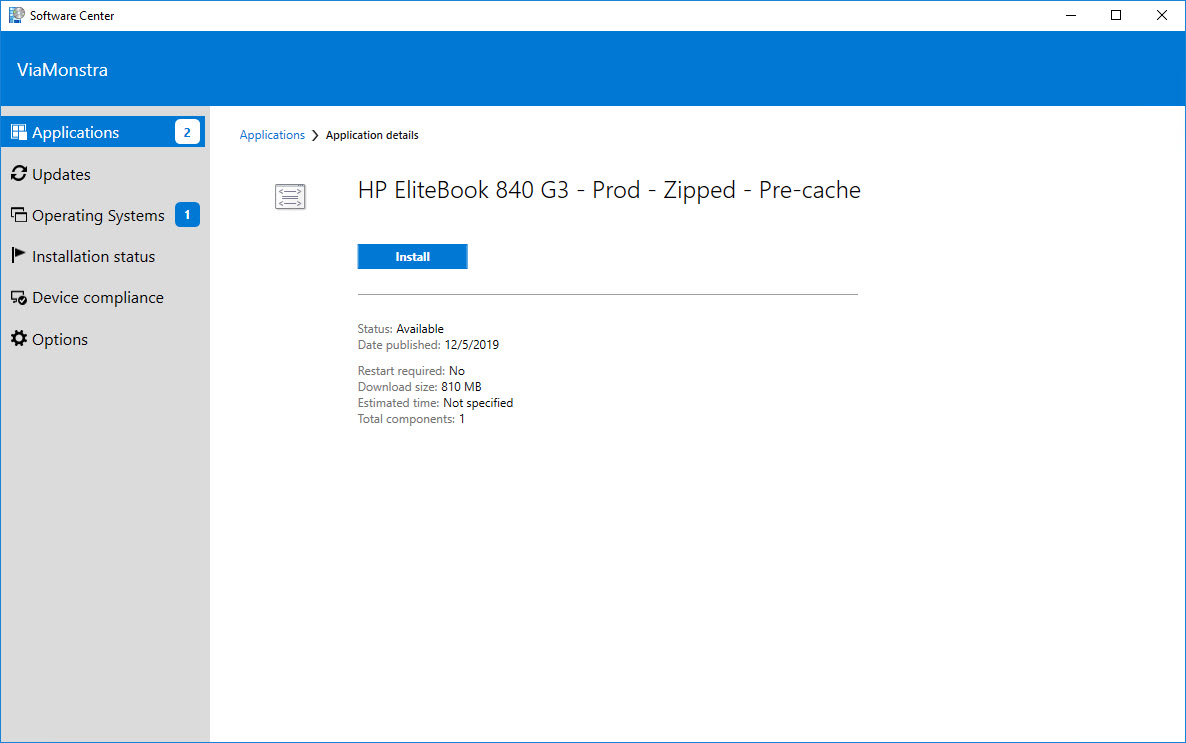
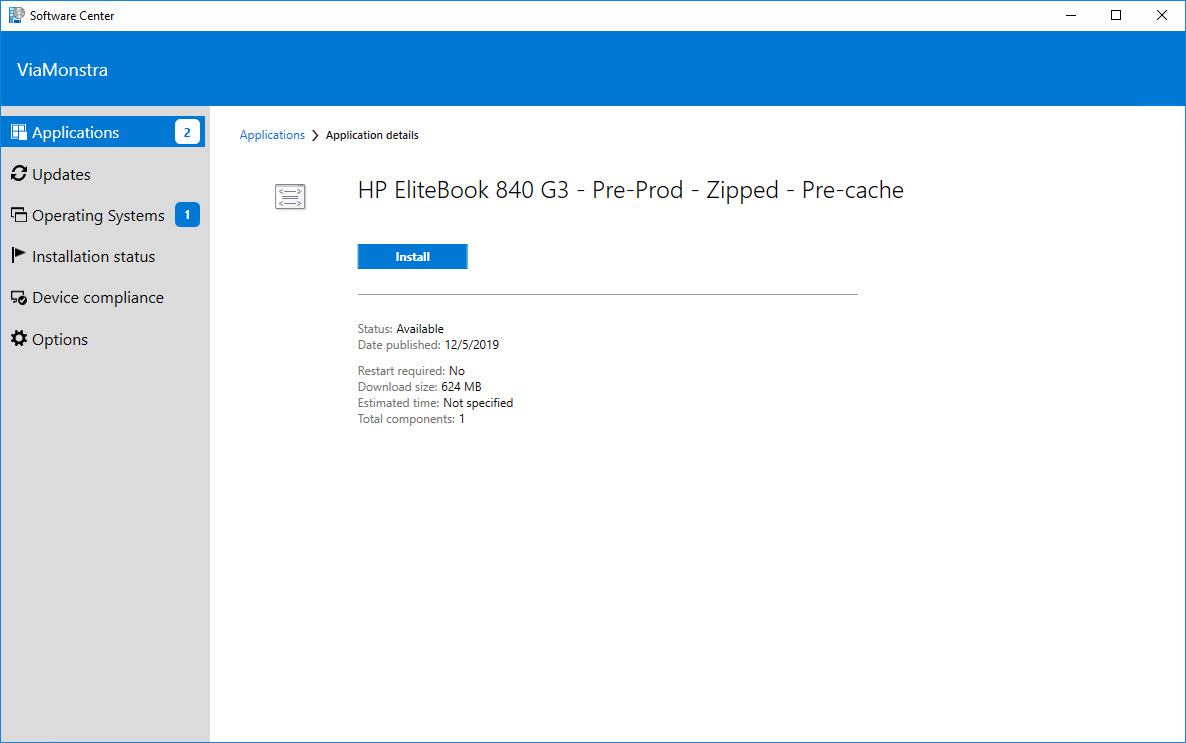
We have been working on a driver package strategy lately and we will probably try to present on it at MMSMOA 2020. The basic concept with all of our IPU and OSD content is that we have a production (Prod) version and a pre-production (Pre-prod) version. This way we can test and certify any changes before they get pushed to production. For driver packages, we are looking at getting even more efficiencies since these are one of the larger types of content on the network. In my example, I will be taking two different driver package versions for the HP Elitebook 840 G3. For our production package we will use SP93541 and for the pre-production package we will use SP96613.
Prod expanded size: 1.93 GB
Pre-prod expanded size: 1.45 GB
If you are using straight up CM and you sent both of these packages, you would be using 3.38 GB of network. So let’s see what happens if we zip them with the PowerShell command Compress-Archive and use Optimal compression:
Prod zip (optimal): 810 MB
Pre-prod zip (optimal): 624 MB
Combined they are now only 1.40 GB – a 1.98 GB savings! Now the big question is, can we get even more efficiency from BranchCache and data deduplication? Absolutely!! However, the first thing to point out is that not all zip compression algorithms are dedup friendly as the really aggressive ones scramble and compress the content as much as possible (like Software Updates).
Step 1 – Download the Prod Zipped Driver Package
For this test, I have created a simple Package-Program that does nothing more than caches the content (cmd /c). Prior to starting the test, I flushed the BranchCache cache and the CCM Cache.
Step 2 – Get the BITS job ID and monitor with BCMon
The BITS job ID can be found using the deprecated BITSADMIN:
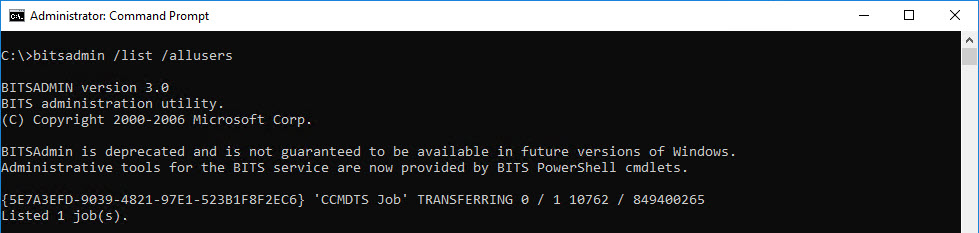
Or by using the PowerShell command Get-BitsTransfer and then run the free BCMon utility from 2Pint Software passing it the BITS Job ID:
![]()
Here we can see that we got 786.65 MB from the server and 23.40 MB from BranchCache:

You might be wondering how this is possible since I flushed the cache before starting. Well, it means that the zip file itself was able to be be deduped, meaning there were some redundant file blocks in the zip file (hint: the same thing can happen on WIM files but at an even greater scale).
Step 3 – Download the Pre-prod Zipped Driver Package
Step 4 – Get the BITS job ID and monitor with BCMon

Here we can see that we got only 113.64 MB from the server and 510.51 MB from BranchCache for a whopping 81.79% efficiency!!! Starting at 3.38 GB, we managed to only send about 900 MB across the network. Also, this is what I like to call a single dimensional test since I only had one client on the network for testing. If there are other clients on the network and they have some of the necessary file blocks (not necessarily the same CM package), then clients will pull from them vs going back to the DP. BranchCache could care less about CM Package IDs or App DT Content ID – this is something that severely limits P2P efficiency in other P2P technologies, like the native CM Peer Cache or 1E Nomad. These technologies only operate at the CM Package ID or App DT Content ID level. In other words, there can be two peers on the same network with 99.99% of the same content but just in a different Package and the two will never share.
BranchCache FTW (even with zip files)!
Originally posted on https://miketerrill.net/



Pingback: BITS Download – from HTTP (DP) – GARYTOWN ConfigMgr Blog